import warningsimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom matplotlib import animationfrom sklearn.datasets import fetch_openmlfrom sklearn.decomposition import PCAnp.seterr(divide="ignore", invalid="ignore")warnings.simplefilter("ignore", RuntimeWarning)warnings.filterwarnings("ignore")
Introduction
I have found that one of the best ways to truly understanding any statistical algorithm or methodology is to manually implement it yourself. On the flip side, coding these algorithms can sometimes be time consuming and a real pain, and when somebody else has already done it, why would I want to spend my time doing it — seems inefficient, no? Both are fair points, and I am not here to make an argument for one over the other.
This article is designed for readers who are interested in understanding t-SNE via translation of the mathematics in the original paper — by Laurens van der Maaten & Geoffrey Hinton — into python code implementation.1 I find these sort of exercises to be quite illuminating into the inner workings of statistical algorithms/models and really test your underlying understanding and assumptions regarding these algorithms/models. You are almost guaranteed to walk away with a better understanding then you had before. At the very minimum, successful implementation is always very satisfying!
This article will be accessible to individuals with any level of exposure of t-SNE. However, note a few things this post definitely is not:
A strictly conceptual introduction and exploration of t-SNE, as there are plenty of other great resources out there that do this; nevertheless, I will be doing my best to connect the mathematical equations to their intuitive/conceptual counterparts at each stage of implementation.
A comprehensive discussion into the applications & pros/cons of t-SNE, as well as direct comparisons of t-SNE to other dimensionality reduction techniques. I will, however, briefly touch on these topics throughout this article, but will by no means cover this in-depth.
Without further ado, let’s start with a brief introduction into t-SNE.
A Brief Introduction to t-SNE
t-distributed stochastic neighbor embedding (t-SNE) is a dimensionality reduction tool that is primarily used in datasets with a large dimensional feature space and enables one to visualize the data down, or project it, into a lower dimensional space (usually 2-D). It is especially useful for visualizing non-linearly separable data wherein linear methods such as Principal Component Analysis (PCA) would fail. Generalizing linear frameworks of dimensionality reduction (such as PCA) into non-linear approaches (such as t-SNE) is also known as Manifold Learning. These methods can be extremely useful for visualizing and understanding the underlying structure of a high dimensional, non-linear data set, and can be great for disentangling and grouping together observations that are similar in the high-dimensional space. For more information on t-SNE and other manifold learning techniques, the scikit-learn documentation is a great resource. Additionally, to read about some cool areas t-SNE has seen applications, the Wikipedia page highlights some of these areas with references to the work.
Let’s start with breaking down the name t-distributed stochastic neighbor embedding into its components. t-SNE is an extension on stochastic neighbor embedding (SNE) presented 6 years earlier in this paper by Geoffrey Hinton & Sam Roweis. So let’s start there. The stochastic part of the name comes from the fact that the objective function is not convex and thus different results can arise from different initializations. The neighbor embedding highlights the nature of the algorithm — optimally mapping the points in the original high-dimensional space into the corresponding low-dimensional space while best preserving the “neighborhood” structure of the points. SNE is comprised of the following (simplified) steps:
Obtain the Similarity Matrix between Points in the Original Space: Compute the conditional probabilities for each datapoint \(j\) relative to each datapoint \(i\). These conditional probabilities are calculated in the original high-dimensional space using a Gaussian centered at \(i\) and take on the following interpretation: the probability that i would pick \(j\) as its neighbor in the original space. This creates a matrix that represents similarities between the points.
Initialization: Choose random starting points in the lower-dimensional space (say, 2-D) for each datapoint in the original space and compute new conditional probabilities similarly as above in this new space.
Mapping: Iteratively improve upon the points in the lower-dimensional space until the Kullback-Leibler divergences between all the conditional probabilities is minimized. Essentially we are minimizing the differences in the probabilities between the similarity matrices of the two spaces so as to ensure the similarities are best preserved in the mapping of the original high-dimensional dataset to the low-dimensional dataset.
t-SNE improves upon SNE in two primary ways:
It minimizes the Kullback-Leibler divergences between the joint probabilities rather than the conditional probabilities. The authors refer to this as “symmetric SNE” b/c their approach ensures that the joint probabilities \(p_ij\) = \(p_ji\). This results in a much better behaved cost function that is easier to optimize.
It computes the similarities between points using a student’s t-distribution w/ one degree of freedom (also a Cauchy Distribution) rather than a Gaussian in the low-dimensional space (step 2 above). Here we can see where the “t” in t-SNE is coming from. This improvement helps to alleviate the “crowding problem” highlighted by the authors and to further improve the optimization problem. This “crowding problem” can be envisioned as such: Imagine we have a 10-D space, the amount of space available in 2-D will not be sufficient to accurately capture those moderately dissimilar points compared to the amount of space for nearby points relative to the amount of space available in a 10-D space. More simply, just envision taking a 3-D space and projecting it down to 2-D, the 3-D space will have much more overall space to model the similarities relative to the projection down into 2-D. The Student-t distribution helps alleviate this problem by having heavier tails than the normal distribution. See the original paper for a much more in-depth treatment of this problem.
If this did not all track immediately, that is okay! I am hoping when we implement this in code, the pieces will all fall in to place. The main takeaway is this: t-SNE models similarities between datapoints in the high-dimensional space using joint probabilities of “datapoints choosing others as its neighbor”, and then tries to find the best mapping of these points down into the low-dimensional space, while best preserving the original high-dimensional similarities.
Implementation from Scratch
Let’s now move on to understanding t-SNE via implementing the original version of the algorithm as presented in the paper by Laurens van der Maaten & Geoffrey Hinton. We will first start with implementing algorithm 1 below step-by-step, which will cover 95% of the main algorithm. There are two additional enhancements the authors note: 1) Early Exaggeration & 2) Adaptive Learning Rates. We will only discuss adding in the early exaggeration as that is most conducive in aiding the interpretation of the actual algorithms inner workings, as the adaptive learning rate is focused on improving the rates of convergence.
1. Inputs
Following the original paper, we will be using the publicly available MNIST dataset from OpenML with images of handwritten digits from 0–9.2 We will also randomly sample 1000 images from the dataset & reduce the dimensionality of the dataset using Principal Component Analysis (PCA) and keep 30 components. These are both to improve computational time of the algorithm, as the code here is not optimized for speed, but rather for interpretability & learning.
This will be our X dataset with each row being an image and each column being a feature, or principal component in this case (i.e. linear combinations of the original pixels):
Code
pd.DataFrame(X)
0
1
2
3
4
5
6
7
8
9
...
20
21
22
23
24
25
26
27
28
29
0
-931.915201
411.259681
-66.223330
-22.101824
-522.071794
-204.238021
79.810311
-151.501689
-2.645304
-71.409799
...
48.977339
64.932067
82.663785
81.841769
113.573963
-289.648157
-37.536887
44.385295
-33.734615
116.867908
1
-498.965271
257.802505
-448.205554
-385.294813
349.350506
-672.517543
-635.617347
127.445850
91.703337
78.129701
...
14.600850
104.047832
-61.352867
79.213565
40.009029
-305.744439
-452.102839
-0.012526
129.821085
-51.821047
2
-653.828524
180.805708
-37.946817
-178.391590
-753.344540
87.362490
-273.592196
141.444895
-237.866486
131.811097
...
-48.118871
-13.359654
198.588208
-37.209171
9.447840
71.514532
-25.251364
14.821461
-139.170878
-80.313444
3
27.990477
392.334507
477.493165
40.194836
505.795588
136.666229
58.409040
-101.268468
-179.489579
-194.865054
...
-243.163467
-175.022793
259.175164
471.665036
173.720381
-21.926315
40.559378
121.260797
-103.262280
-174.272627
4
108.686834
-443.761169
1047.275507
-269.081714
698.282492
268.993661
2.649905
227.015596
590.552236
64.509176
...
34.180812
-14.272677
-4.267202
-380.389612
233.763787
-196.247229
-21.257888
-144.816963
-130.726495
105.042093
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
995
704.001866
416.201728
728.202071
545.738046
-13.182785
168.897764
-252.975670
-3.950580
-212.479052
-567.985417
...
327.495047
44.757261
11.850213
-324.565843
-103.983645
-79.764025
486.828049
-174.229356
-399.590480
-207.753263
996
-435.583186
-518.925730
523.326068
273.215373
-281.536846
368.020921
-30.906676
-86.819580
130.227015
227.218531
...
4.785787
-84.410557
-304.009573
13.309568
-254.705140
-115.894610
96.160201
97.570096
-40.360102
196.480744
997
290.048713
-123.651858
38.271626
-788.843811
-219.241666
547.644998
-41.129062
-400.736268
-440.175055
-339.627691
...
70.933713
415.261998
-277.123724
68.509559
79.043054
205.682516
191.826804
209.089092
-292.390174
-24.164274
998
-81.494684
-893.865631
284.655251
-193.626306
208.005578
108.519770
-138.118422
-44.223366
-223.193259
345.672341
...
297.352410
89.948871
-19.759266
-122.929192
-1.523811
103.019254
-240.920921
117.842351
-171.811250
-268.943841
999
-237.792154
-449.364853
993.977356
-20.240607
-83.963739
197.301905
198.658445
404.901898
526.368305
368.054294
...
-76.226814
-66.050405
-62.809371
43.364113
-449.005920
-266.624174
211.255202
74.683071
147.336721
343.400059
1000 rows × 30 columns
We also will need to specify the cost function parameters — perplexity — and the optimization parameters — iterations, learning rate, & momentum. We will hold off on these for now and address them as they appear at each stage.
In terms of output, recall that we seek a the low-dimensional mapping of the original dataset X. We will be mapping the original space into a 2 dimensional space throughout this example. Thus, our new output will be the 1000 images now represented in a 2 dimensional space rather than the original 30 dimensional space, with a shape of [1000, 2].
2. Compute Affinities/Similarities of X in the Original Space
Now that we have our inputs, the first step is to compute the pairwise similarities in the original high dimensional space. That is, for each image \(i\) we compute the probability that \(i\) would pick image \(j\) as its neighbor in the original space for each \(j\). These probabilities are calculated via a normal distribution centered around each point and then are normalized to sum up to 1. Mathematically, we have:
Note that, in our case with n = 1000, these computations will result in a 1000 x 1000 matrix of similarity scores. Note we set \(p\) = 0 whenever \(i\) = \(j\) b/c we are modeling pairwise similarities. However, you may notice that we have not mentioned how \(\sigma\) is determined. This value is determined for each observation \(i\) via a grid search based on the user-specified desired perplexity of the distributions. We will talk about this immediately below, but let’s first look at how we would code eq. (1) above:
Code
def get_original_pairwise_affinities( X: np.ndarray, perplexity: int=10) -> np.ndarray:""" Function to obtain affinities matrix. Parameters ---------- X The input data array. perplexity The perplexity value for the grid search. Returns ------ np.ndarray The pairwise affinities matrix. """ n =len(X)print("Computing Pairwise Affinities....") p_ij = np.zeros(shape=(n, n))for i inrange(0, n):# Equation 1 numerator diff = X[i] - X σ_i = grid_search(diff, i, perplexity) # Grid Search for σ_i norm = np.linalg.norm(diff, axis=1) p_ij[i, :] = np.exp(-(norm**2) / (2* σ_i**2))# Set p = 0 when j = i np.fill_diagonal(p_ij, 0)# Equation 1 p_ij[i, :] = p_ij[i, :] / np.sum(p_ij[i, :])# Set 0 values to minimum numpy value (ε approx. = 0) ε = np.nextafter(0, 1) p_ij = np.maximum(p_ij, ε)print("Completed Pairwise Affinities Matrix. \n")return p_ij
Now before we look at the results of this code, let’s discuss how we determine the values of \(\sigma\) via the grid_search() function. Given a specified value of perplexity (which in this context can be loosely thought about as the number of nearest neighbors for each point), we do a grid search over a range of values of \(\sigma\) such that the following equation is as close to equality as possible for each \(i\):
In our case, we will set perplexity = 10 and set the search space to be defined by [0.01 * standard deviation of the norms for the difference between images \(i\) and \(j\), 5 * standard deviation of the norms for the difference between images \(i\) and \(j\)] divided into 200 equal steps. Knowing this, we can define our grid_search() function as follows:
Code
def grid_search(diff_i: np.ndarray, i: int, perplexity: int) ->float:""" Helper function to obtain σ's based on user-specified perplexity. Parameters ----------- diff_i Array containing the pairwise differences between data points. i Index of the current data point. perplexity User-specified perplexity value. Returns ------- float The value of σ that satisfies the perplexity condition. """ result = np.inf # Set first result to be infinity norm = np.linalg.norm(diff_i, axis=1) std_norm = np.std( norm ) # Use standard deviation of norms to define search spacefor σ_search in np.linspace(0.01* std_norm, 5* std_norm, 200):# Equation 1 Numerator p = np.exp(-(norm**2) / (2* σ_search**2))# Set p = 0 when i = j p[i] =0# Equation 1 (ε -> 0) ε = np.nextafter(0, 1) p_new = np.maximum(p / np.sum(p), ε)# Shannon Entropy H =-np.sum(p_new * np.log2(p_new))# Get log(perplexity equation) as close to equalityif np.abs(np.log(perplexity) - H * np.log(2)) < np.abs(result): result = np.log(perplexity) - H * np.log(2) σ = σ_searchreturn σ
Given these functions, we can compute the affinity matrix via:
Note, the diagonal elements are set to \(\epsilon \approx 0\) by construction (whenever \(i\) = \(j\)). Recall that a key extension of the t-SNE algorithm is to compute the joint probabilities rather than the conditional probabilities. This is computed simply as follow:
Now we have completed the first main step in t-SNE! We computed the symmetric affinity matrix in the original high-dimensional space. Before we dive right into the optimization stage, we will discuss the main components of the optimization problem in the next two steps and then combine them into our for loop.
Now we want to sample a random initial solution in the lower dimensional space as follows:
Code
def initialization( X: np.ndarray, n_dimensions: int=2, initialization: str="random") -> np.ndarray:""" Obtain initial solution for t-SNE either randomly or using PCA. Parameters ---------- X The input data array. n_dimensions The number of dimensions for the output solution. Default is 2. initialization The initialization method. Can be 'random' or 'PCA'. Default is 'random'. Returns ------- np.ndarray The initial solution for t-SNE. Raises ------- ValueError If the initialization method is neither 'random' nor 'PCA'. """# Sample Initial Solutionif initialization =="random"or initialization !="PCA": y0 = np.random.normal(loc=0, scale=1e-4, size=(len(X), n_dimensions))elif initialization =="PCA": X_centered = X - X.mean(axis=0) _, _, Vt = np.linalg.svd(X_centered) y0 = X_centered @ Vt.T[:, :n_dimensions]else:raiseValueError("Initialization must be 'random' or 'PCA'")return y0
Code
y0 = initialization(X)
Code
pd.DataFrame(y0)
0
1
0
-0.000006
-0.000083
1
-0.000061
-0.000056
2
0.000125
-0.000092
3
-0.000007
0.000005
4
0.000079
-0.000019
...
...
...
995
0.000128
0.000066
996
0.000113
-0.000063
997
-0.000060
0.000040
998
0.000073
-0.000030
999
0.000195
-0.000062
1000 rows × 2 columns
Now, we want to compute the affinity matrix in this lower dimensional space. However, recall that we do this utilizing a student’s t-distribution w/ 1 degree of freedom:
Again, we set \(q=0\) whenever \(i = j\). Note this equation differs from eq. (1) in that the denominator is over all \(i\) and thus symmetric by construction. Putting this into code, we obtain:
Code
def get_low_dimensional_affinities(Y: np.ndarray) -> np.ndarray:""" Obtain low-dimensional affinities. Parameters ----------- Y The low-dimensional representation of the data points. Returns ------- np.ndarray The low-dimensional affinities matrix. """ n =len(Y) q_ij = np.zeros(shape=(n, n))for i inrange(0, n):# Equation 4 Numerator diff = Y[i] - Y norm = np.linalg.norm(diff, axis=1) q_ij[i, :] = (1+ norm**2) ** (-1)# Set p = 0 when j = i np.fill_diagonal(q_ij, 0)# Equation 4 q_ij = q_ij / q_ij.sum()# Set 0 values to minimum numpy value (ε approx. = 0) ε = np.nextafter(0, 1) q_ij = np.maximum(q_ij, ε)return q_ij
Here we are seeking a 1000 x 1000 affinity matrix but now in the lower dimensional space:
Code
q_ij = get_low_dimensional_affinities(y0)
Code
pd.DataFrame(q_ij)
0
1
2
3
4
5
6
7
8
9
...
990
991
992
993
994
995
996
997
998
999
0
4.940656e-324
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1
1.001001e-06
4.940656e-324
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
2
1.001001e-06
1.001001e-06
4.940656e-324
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
3
1.001001e-06
1.001001e-06
1.001001e-06
4.940656e-324
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
4
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
4.940656e-324
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
995
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
4.940656e-324
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
996
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
4.940656e-324
1.001001e-06
1.001001e-06
1.001001e-06
997
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
4.940656e-324
1.001001e-06
1.001001e-06
998
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
4.940656e-324
1.001001e-06
999
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
0.000001
0.000001
0.000001
0.000001
0.000001
...
0.000001
0.000001
0.000001
0.000001
0.000001
1.001001e-06
1.001001e-06
1.001001e-06
1.001001e-06
4.940656e-324
1000 rows × 1000 columns
4. Compute Gradient of the Cost Function
Recall, our cost function is the Kullback-Leibler divergence between joint probability distributions in the high dimensional space and low dimensional space:
Intuitively, we want to minimize the difference in the affinity matrices \(p_{ij}\) and \(q_{ij}\) thereby best preserving the “neighborhood” structure of the original space. The optimization problem is solved using gradient descent, but first let’s look at computing the gradient for the cost function above. The authors derive (see appendix A of the paper) the gradient of the cost function as follows:
def get_gradient(p_ij: np.ndarray, q_ij: np.ndarray, Y: np.ndarray) -> np.ndarray:""" Obtain gradient of cost function at current point Y. Parameters ---------- p_ij The joint probability distribution matrix. q_ij The Student's t-distribution matrix. Y The current point in the low-dimensional space. Returns ------ np.ndarray The gradient of the cost function at the current point Y. """ n =len(p_ij)# Compute gradient gradient = np.zeros(shape=(n, Y.shape[1]))for i inrange(0, n):# Equation 5 diff = Y[i] - Y A = np.array([(p_ij[i, :] - q_ij[i, :])]) B = np.array([(1+ np.linalg.norm(diff, axis=1) **2) ** (-1)]) C = diff gradient[i] =4* np.sum((A * B).T * C, axis=0)return gradient
Feeding in the relevant arguments, we obtain the gradient as follows:
Code
gradient = get_gradient(p_ij_symmetric, q_ij, y0)
Code
pd.DataFrame(gradient)
0
1
0
-1.286946e-07
-9.462969e-09
1
1.707158e-09
-1.425793e-09
2
2.251103e-07
4.674707e-08
3
9.274299e-08
6.214602e-08
4
-2.121515e-07
1.341276e-07
...
...
...
995
-2.399576e-07
-2.276706e-07
996
-1.773476e-07
1.952968e-07
997
-2.348704e-07
-2.571400e-08
998
9.532368e-08
1.930476e-07
999
-2.434140e-07
1.972993e-08
1000 rows × 2 columns
Now, we have all the pieces in order to solve the optimization problem!
where \(\eta\) is our learning rate and \(\alpha(t)\) is our momentum term as a function of time. The learning rate controls the step size at each iteration and the momentum term allows the optimization algorithm to gain inertia in the smooth direction of the search space, while not being bogged down by the noisy parts of the gradient. We will set \(\eta=200\) for our example and will fix \(\alpha(t)=0.5\) if \(t < 250\) and \(\alpha(t)=0.8\) otherwise. We have all the components necessary above to compute to the update rule, thus we can now run our optimization over a set number of iterations \(T\) (we will set \(T=1000\)).
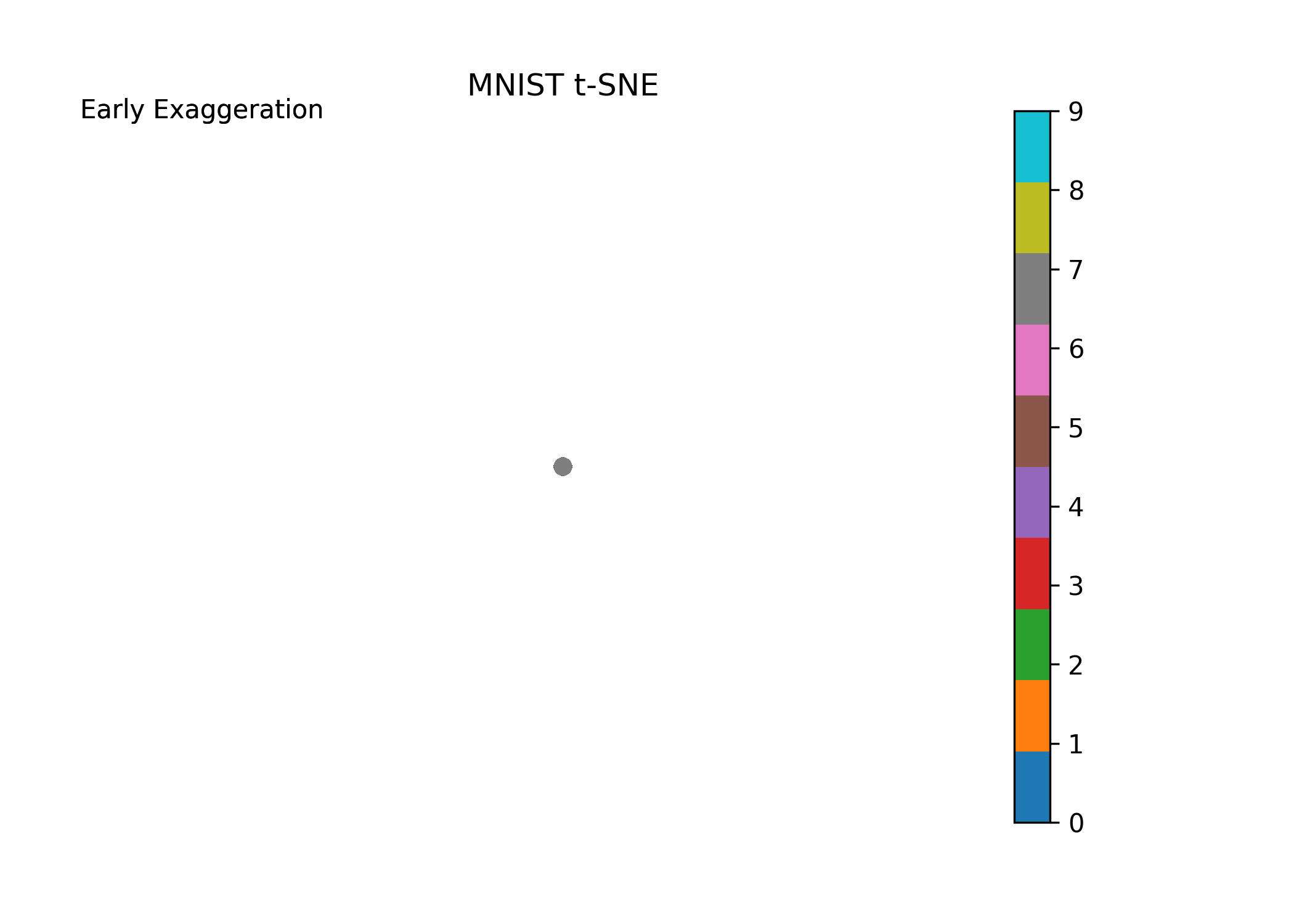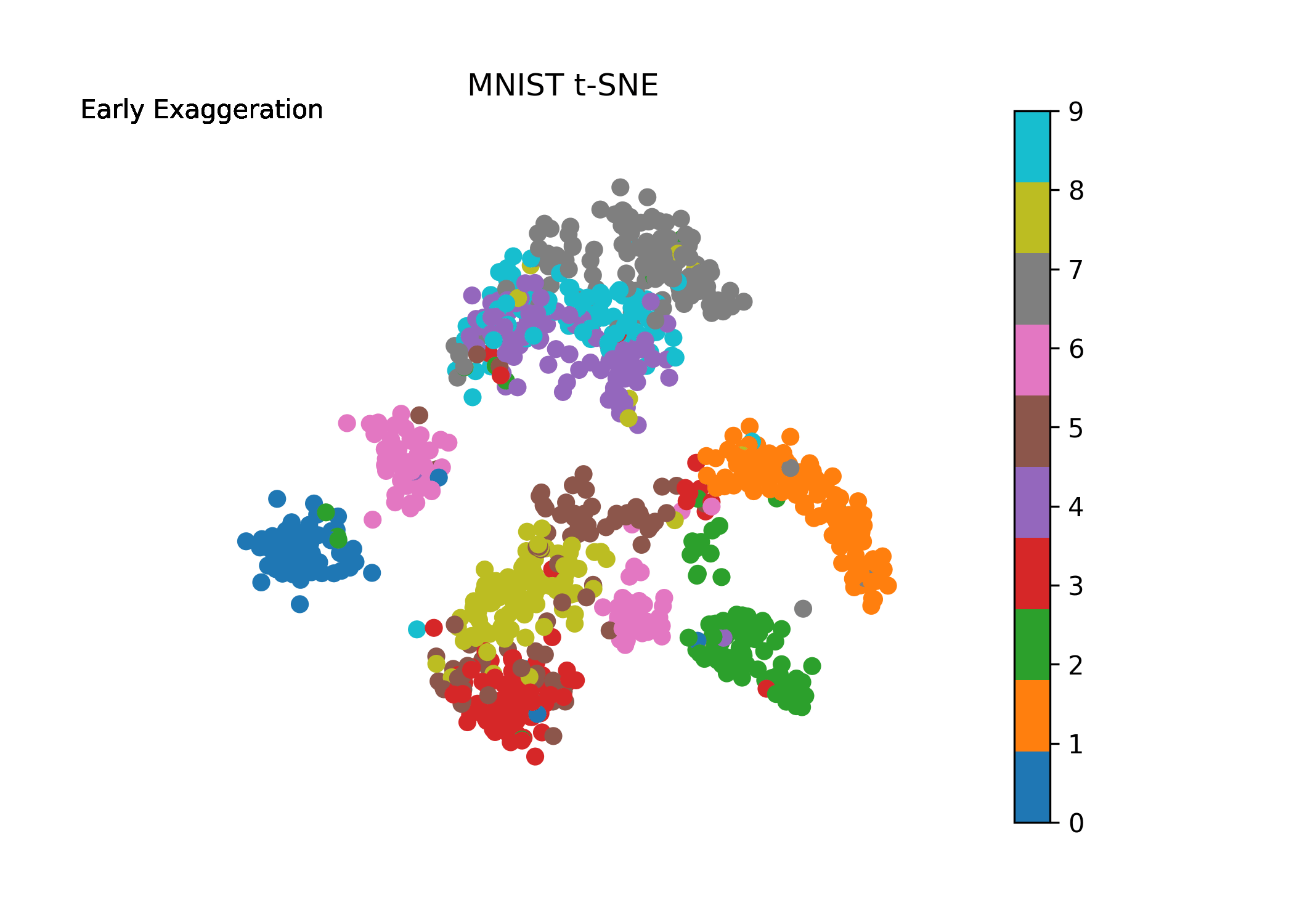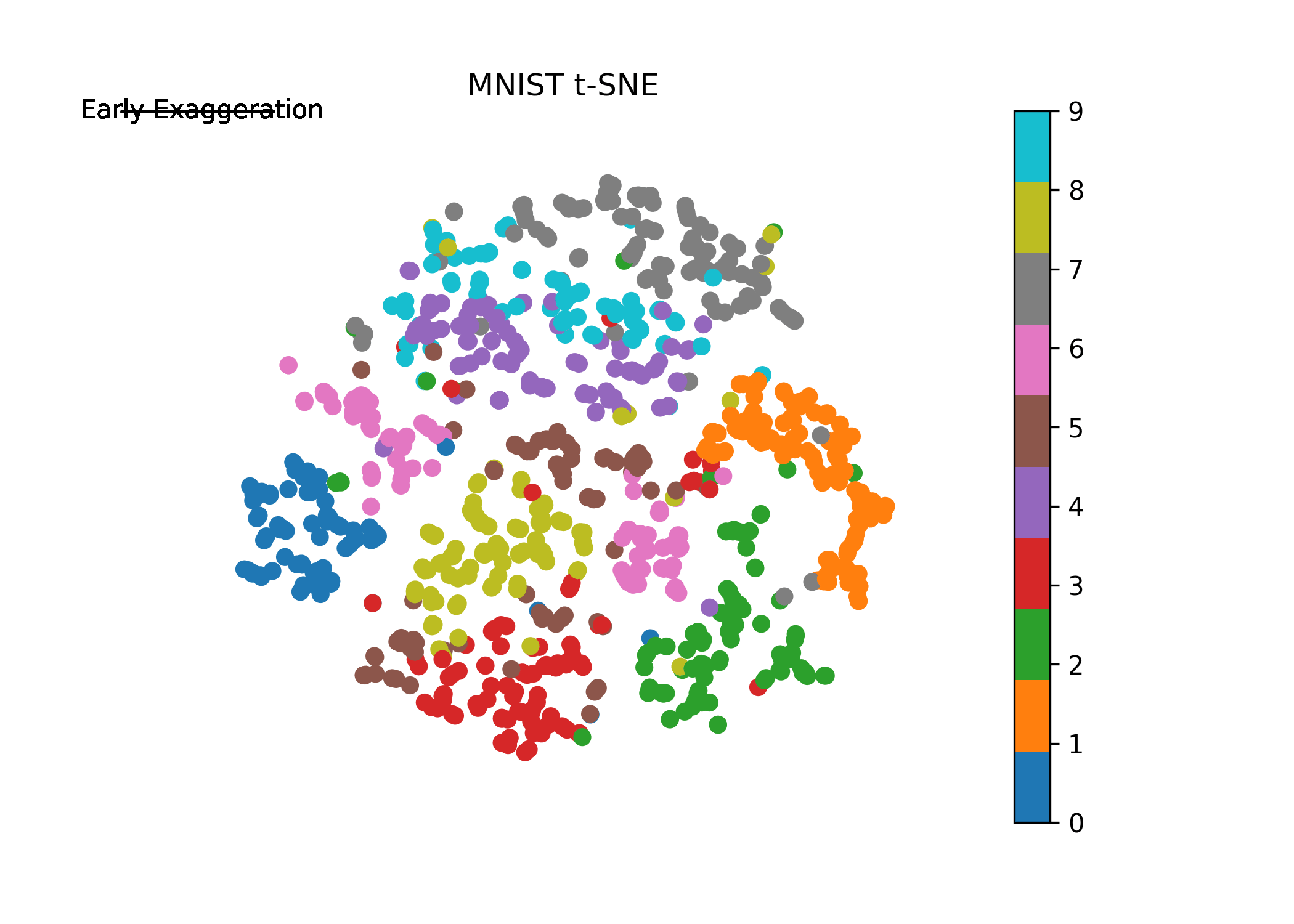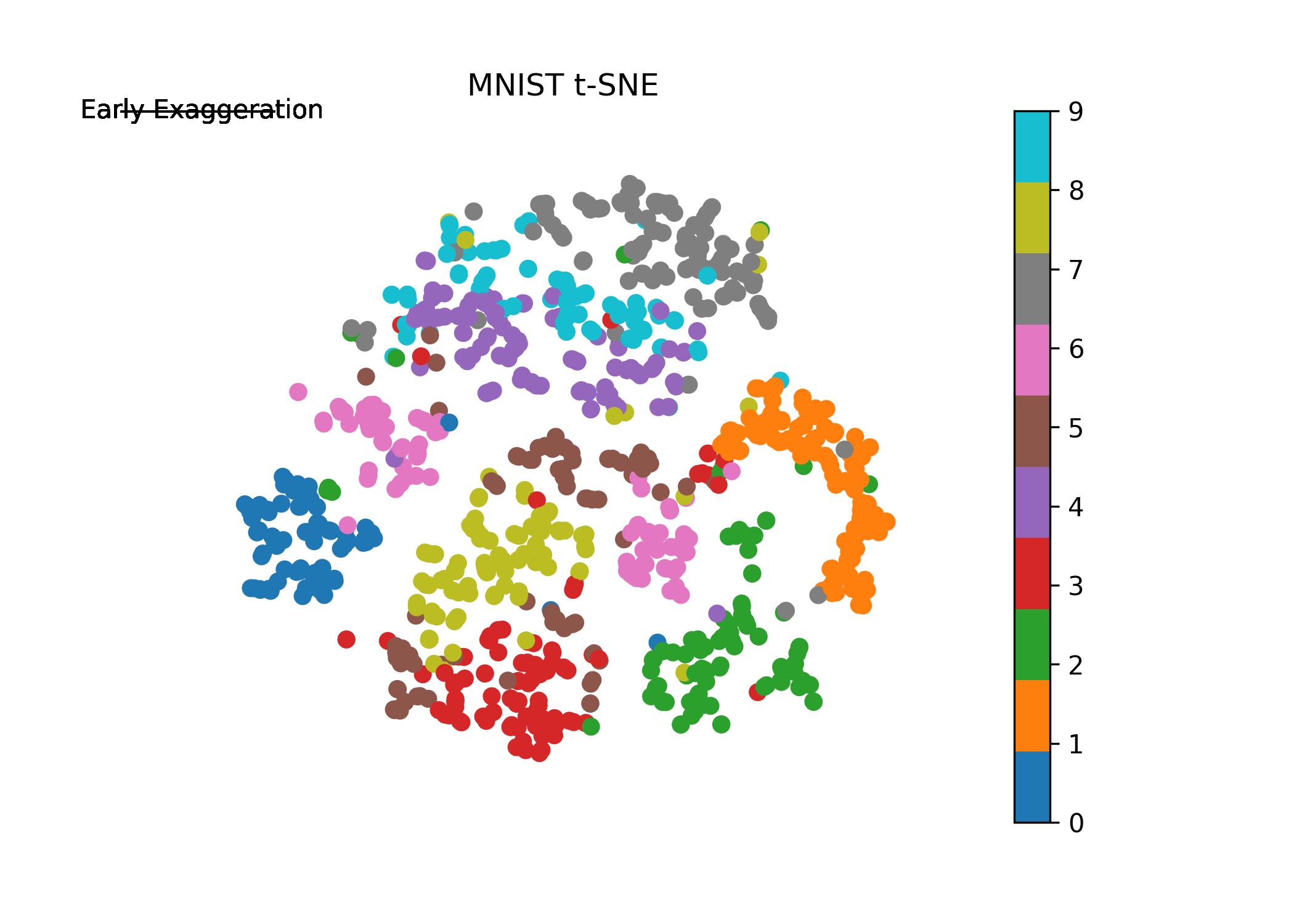
Before we set up for iteration scheme, let’s first introduce the enhancement the authors refer to as “early exaggeration”. This term is a constant that scales the original matrix of affinities \(p_{ij}\). What this does is it places more emphasis on modeling the very similar points (high values in \(p_{ij}\) from the original space) in the new space early on and thus forming “clusters” of highly similar points. The early exaggeration is placed on at the beginning of the iteration scheme (\(T<250\)) and then turned off otherwise. Early exaggeration will be set to 4 in our case. We will see this in action in our visual below following implementation.
Now, putting all of the pieces together for the algorithm, we have the following:
Code
def tsne( X: np.ndarray, perplexity: int=10, T: int=1000, η: int=200, early_exaggeration: int=4, n_dimensions: int=2,) ->list[np.ndarray, np.ndarray]:""" t-SNE (t-Distributed Stochastic Neighbor Embedding) algorithm implementation. Parameters ---------- X The input data matrix of shape (n_samples, n_features). perplexity The perplexity parameter. Default is 10. T The number of iterations for optimization. Default is 1000. η The learning rate for updating the low-dimensional embeddings. Default is 200. early_exaggeration The factor by which the pairwise affinities are exaggerated during the early iterations of optimization. Default is 4. n_dimensions The number of dimensions of the low-dimensional embeddings. Default is 2. Returns ------- list[np.ndarray, np.ndarray] A list containing the final low-dimensional embeddings and the history of embeddings at each iteration. """ n =len(X)# Get original affinities matrix p_ij = get_original_pairwise_affinities(X, perplexity) p_ij_symmetric = get_symmetric_p_ij(p_ij)# Initialization Y = np.zeros(shape=(T, n, n_dimensions)) Y_minus1 = np.zeros(shape=(n, n_dimensions)) Y[0] = Y_minus1 Y1 = initialization(X, n_dimensions) Y[1] = np.array(Y1)print("Optimizing Low Dimensional Embedding....")# Optimizationfor t inrange(1, T -1):# Momentum & Early Exaggerationif t <250: α =0.5 early_exaggeration = early_exaggerationelse: α =0.8 early_exaggeration =1# Get Low Dimensional Affinities q_ij = get_low_dimensional_affinities(Y[t])# Get Gradient of Cost Function gradient = get_gradient(early_exaggeration * p_ij_symmetric, q_ij, Y[t])# Update Rule Y[t +1] = ( Y[t] - η * gradient + α * (Y[t] - Y[t -1]) ) # Use negative gradient# Compute current value of cost functionif t %50==0or t ==1: cost = np.sum(p_ij_symmetric * np.log(p_ij_symmetric / q_ij))print(f"Iteration {t}: Value of Cost Function is {cost}")print(f"Completed Low Dimensional Embedding: Final Value of Cost Function is {np.sum(p_ij_symmetric * np.log(p_ij_symmetric / q_ij))}" ) solution = Y[-1]return solution, Y
Now calling the code:
Code
solution, Y = tsne(X)
Computing Pairwise Affinities....
Completed Pairwise Affinities Matrix.
Computing Symmetric p_ij matrix....
Completed Symmetric p_ij Matrix.
Optimizing Low Dimensional Embedding....
Iteration 1: Value of Cost Function is 4.4406978130558805
Iteration 50: Value of Cost Function is 2.962401546326715
Iteration 100: Value of Cost Function is 2.700973774872353
Iteration 150: Value of Cost Function is 2.626831291889962
Iteration 200: Value of Cost Function is 2.5857498685122136
Iteration 250: Value of Cost Function is 2.564941209380378
Iteration 300: Value of Cost Function is 1.5533671265166362
Iteration 350: Value of Cost Function is 1.3730253404956603
Iteration 400: Value of Cost Function is 1.2803489722973787
Iteration 450: Value of Cost Function is 1.2212705755480584
Iteration 500: Value of Cost Function is 1.1794021107310177
Iteration 550: Value of Cost Function is 1.147752347037585
Iteration 600: Value of Cost Function is 1.12276586088434
Iteration 650: Value of Cost Function is 1.1024151891121186
Iteration 700: Value of Cost Function is 1.0854616699236224
Iteration 750: Value of Cost Function is 1.071036433368177
Iteration 800: Value of Cost Function is 1.058604345842621
Iteration 850: Value of Cost Function is 1.0477978673444914
Iteration 900: Value of Cost Function is 1.038290429912608
Iteration 950: Value of Cost Function is 1.029831423205263
Completed Low Dimensional Embedding: Final Value of Cost Function is 1.0225388914762061
Code
pd.DataFrame(solution)
0
1
0
34.014055
1.542836
1
35.155558
-16.882073
2
13.360120
-2.866010
3
-8.949272
-14.304973
4
-16.397379
23.816197
...
...
...
995
-8.576599
-26.687632
996
-3.064378
32.732870
997
-19.259571
7.352250
998
-9.212013
19.369818
999
-4.722223
35.397239
1000 rows × 2 columns
where solution is the final 2-D mapping and Y is our mapped 2-D values at each step of the iteration. Plotting the evolution of Y where Y[-1] is our final 2-D mapping, we obtain (note how the algorithm behaves with early exaggeration on and off):
I recommend playing around with different values of the parameters (i.e., perplexity, learning rate, early exaggeration, etc.) to see how the solution differs (See the original paper and the scikit-learn documentation for guides on using these parameters).
Conclusion
And there you have it, we have coded t-SNE from scratch! I hope you have found this exercise to be illuminating into the inner workings of t-SNE and, at the very minimum, satisfying. Note that this implementation is not intended to be optimized for speed, but rather for understanding. Additions to the t-SNE algorithm have been implemented to improve computational speed and performance, such as variants of the Barnes-Hut algorithm (tree-based approaches), using PCA as the initialization of the embedding, or using additional gradient descent extensions such as adaptive learning rates. The implementation in scikit-learn makes use of many of these enhancements.
As always, I hope you have enjoyed reading this as much as I enjoyed writing it.
I appreciate you reading my post! My posts primarily explore real-world and theoretical applications of econometric and statistical/machine learning techniques, but also whatever I am currently interested in or learning 😁. At the end of the day, I write to learn! I hope to make complex topics slightly more accessible to all.
Footnotes
van der Maaten, L.J.P.; Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. Journal of Machine Learning Research 9:2579–2605, 2008.↩︎
LeCun et al. (1999): The MNIST Dataset Of Handwritten Digits (Images) License: CC BY-SA 3.0↩︎